Paso 1: Hacer una limpieza de la base de datos, según el análisis que realizamos, entendemos que esta base de datos se hizo una carga masiva, porque el archivo de log es muy grande y tanto el log como la base de datos tienen mucho espacio de sobra. Si esto no es así, saltar al siguiente paso.
- Cambiamos el modo de recuperación de la base de datos a simple, ya que el modo full hace que el log crezca mucho y el propósito es para recuperaciones parciales, si este es el caso, no usar paso.
Commando: Alter database [DataDashboard] set recovery simple
- Limpiamos tanto el log como la base de datos utilizando los siguientes comandos
DBCC SHRINKDATABASE ([DataDashboard]);
DBCC SHRINKFILE([DataDashboard], 0);
GO
DBCC SHRINKFILE([DataDashboard_Log], 0);
GO
Paso 2: Verificamos el tamaño de las tablas, por cantidad de filas y espacio en disco, para identificar oportunidad de mejora, utilizando el script siguiente:
SELECT t.NAME AS TableName,
s.Name AS SchemaName,
p.rows,
SUM(a.total_pages) *8 AS TotalSpaceKB,
CAST(ROUND(((SUM(a.total_pages) *8) /1024.00), 2) AS NUMERIC(36, 2)) AS TotalSpaceMB,
SUM(a.used_pages) *8 AS UsedSpaceKB,
CAST(ROUND(((SUM(a.used_pages) *8) /1024.00), 2) AS NUMERIC(36, 2)) AS UsedSpaceMB,
(SUM(a.total_pages) -SUM(a.used_pages)) *8 AS UnusedSpaceKB,
CAST(ROUND(((SUM(a.total_pages) -SUM(a.used_pages)) *8) /1024.00, 2) AS NUMERIC(36, 2)) AS UnusedSpaceMB
FROM sys.tables t
INNER JOIN sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN sys.partitions p ON i.object_id =p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id
LEFT OUTER JOIN sys.schemas s ON t.schema_id =s.schema_id
WHERE t.is_ms_shipped =0 AND i.OBJECT_ID >255
GROUP BY t.Name, s.Name, p.Rows
ORDER BY TotalSpaceMB DESC, t.Name
Paso 3: Identificamos los índices con necesidad de ser reorganizados, los que necesitaban reconstrucción y además actualizamos las estadísticas, todo eso con el procedimiento almacenado a continuación:
Nota: Debe crearse y luego ejecutarse pasando como parámetro la base de datos.
CREATE PROCEDURE [dbo].[Update_Index_Statistics_Maintenance]
@DBName AS NVARCHAR(128)
AS
DECLARE @ERRORE INT
–Check Database Error
DBCC CHECKDB WITH NO_INFOMSGS
SET @ERRORE = @@ERROR
IF @ERRORE = 0
BEGIN
DECLARE @RC INT
DECLARE @Messaggio VARCHAR(MAX)
DECLARE @Rebild AS VARCHAR(MAX)
DECLARE @Reorganize AS VARCHAR(MAX)
SET @Reorganize = ”
SET @Rebild = ”
SELECT @Reorganize = @Reorganize + ‘ ‘ +
‘ALTER INDEX [‘ + i.[name] + ‘] ON [dbo].[‘ + t.[name] + ‘]
REORGANIZE WITH ( LOB_COMPACTION = ON )’
FROM sys.dm_db_index_physical_stats
(DB_ID(@DBName ), NULL, NULL, NULL , ‘DETAILED’) fi
inner join sys.tables t
on fi.[object_id] = t.[object_id]
inner join sys.indexes i
on fi.[object_id] = i.[object_id] and
fi.index_id = i.index_id
where t.[name] is not null and i.[name] is not null
and avg_fragmentation_in_percent > 10
and avg_fragmentation_in_percent <=35
order by t.[name]
EXEC (@Reorganize)
SELECT @Rebild = @Rebild + ‘ ‘ +
‘ALTER INDEX [‘ + i.[name] + ‘] ON [dbo].[‘ + t.[name] + ‘]
REBUILD WITH (ONLINE = OFF )’
FROM sys.dm_db_index_physical_stats
(DB_ID(@DBName ), NULL, NULL, NULL , ‘DETAILED’) fi
inner join sys.tables t
on fi.[object_id] = t.[object_id]
inner join sys.indexes i
on fi.[object_id] = i.[object_id] and
fi.index_id = i.index_id
where avg_fragmentation_in_percent > 35 and t.[name] is not null and i.[name] is not null
order by t.[name]
EXEC (@Rebild)
END
— if there are not error update statistics
SET @ERRORE = @@ERROR
IF @ERRORE = 0
BEGIN
EXEC sp_updatestats
END
;
Paso 4: Ejecutamos los Dashboards (Pero nos concentramos en “Evolución temporal”), esto con el objetivo de crear un historial de las consultas que tomaron más tiempo en ejecución y que consumieron más recursos.
Con las consultas identificadas nos concentramos en encontrar si había forma de mejorarlas y de ese resultado nos arrojó que la creación de un índice nuevo nos podía mejorar el rendimiento en un 34.51%, como muestra la siguiente figura, además anexamos el script para crear el nuevo índice.
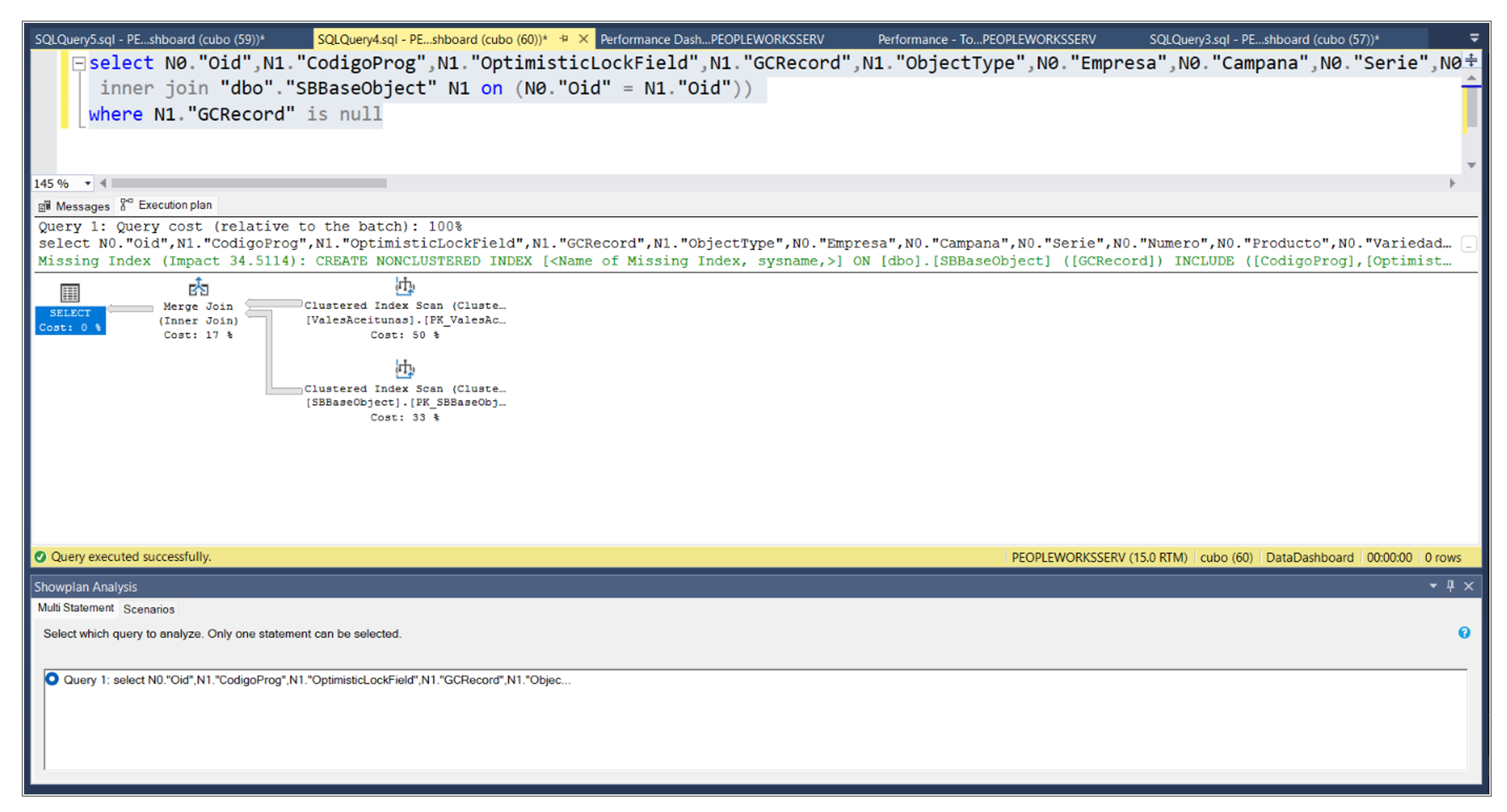
Ejecutar el siguiente Script:
/*
Missing Index Details from SQLQuery4.sql – PEOPLEWORKSSERV.DataDashboard (cubo (60))
The Query Processor estimates that implementing the following index could improve the query cost by 34.5114%.
*/
USE [DataDashboard]
GO
CREATE NONCLUSTERED INDEX IX_SBBaseObject_GCRecord
ON [dbo].[SBBaseObject] ([GCRecord])
INCLUDE ([CodigoProg],[OptimisticLockField],[ObjectType])
GO
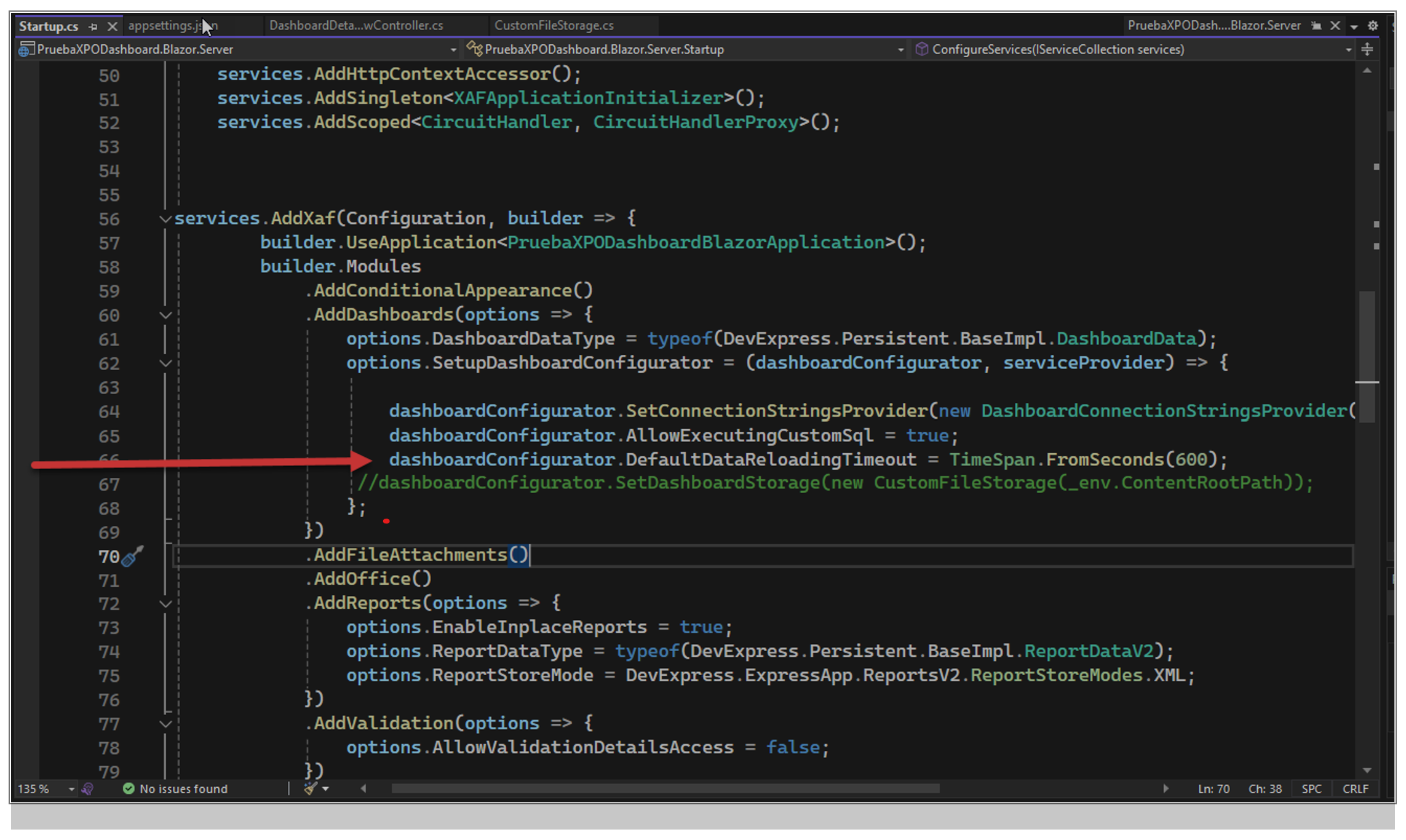
Paso 5: Como tenemos un millón de registros y el Dashboard no tiene ningún parámetro de filtro, debemos crear el tiempo de espera necesario para que la data se cargue completamente, por lo que hemos agregado un parámetro nuevo en el programa “Startup.cs”, que está ubicado en proyecto “PruebaXPODashboard.Blazor.Server”, como mostramos en la figura siguiente:
Comando: El tiempo se puede ampliar, pero entendemos que, con las mejoras antes hechas a la base de datos, es más que suficiente.
dashboardConfigurator.DefaultDataReloadingTimeout = TimeSpan.FromSeconds(600);